主成分分析(PCA)一个功能强大且行之有效的数据转换方法可以实现吗用于数据可视化,降维,并可能通过监督学习任务提高性能. 在这个用例博客中,我们检查了一个数据集,该数据集由良性和恶性肿瘤的测量值组成,这些测量值是从乳腺肿块组织的细针抽吸物的数字图像中计算出来的。具体而言,这30个变量描述了图像中细胞核的特定特征,如纹理对称性和半径。

数据探索
将PCA应用于这一过程的第一步是看看我们是否能更容易地在两个维度上可视化恶性和良性分类之间的分离。为此,我们首先将数据集划分为训练集和测试集,并仅使用训练数据执行PCA。虽然这一步骤可以被认为是特征工程,但在执行PCA之前进行训练-测试分离是很重要的,因为转换考虑了整个数据集的可变性,否则会导致测试集中的信息泄漏到训练数据中。

得到的PCA资源列出了排名靠前的主成分(PC),按照它们的变量百分比进行排序。在这个例子中,我们可以看到PC1占数据集中总方差的45.12%,而前7个pc就占了解释变量的90%。通过检查左边的条形图,我们可以进一步探索哪些原始领域对各种pc的贡献最大。对PC1贡献最大的三个是“凹点平均值”、“凹点平均值”和“凹点最差”。基于这一信息,我们可以开始得出结论,与凹相关的特征是高度可变的,并可能具有区别性。

PCA变换产生新的变量,这些变量是原始字段的线性组合。这种转换的主要优点是,新字段彼此之间不相关,每个连续的主分量在与其他分量正交的约束下寻求最大化数据集中剩余的方差。通过最大化方差和去关联特征,pca创建的变量通常可以在监督学习中表现得更好——尤其是在具有较高偏倚水平的模型类型中。然而,这是以牺牲整体可解释性为代价的。尽管我们总是可以检查原始变量对PCA字段的贡献,但是30个变量的线性组合总是比简单地检查原始变量要简单得多。
数据可视化

在仅根据前2个主成分(PC1和PC2)绘制数据集并根据诊断(良性或恶性)着色每个数据点之后,我们已经可以看到类之间的相当大的分离。这个结果令人印象深刻的是,在创建或选择这些Principal Component字段时,我们没有使用目标变量的知识。我们只是创建了一些字段来解释数据集中最大的差异,它们也被证明具有巨大的辨别力。
预测建模
最后,我们可以评估我们的Principal Components字段作为逻辑回归分类器的输入的工作情况。在我们的评估中,我们使用4组不同的变量训练了一个具有相同超参数(L2正则化,c=1.0,包括偏差项)的逻辑回归模型:
- 所有30个原始变量
- 所有主要组件
- 前7件(90%PVE)
- 只有前2台电脑
结果显示在下面的受试者操作特征(ROC)曲线中,恶性诊断作为阳性分类,并按曲线下面积(AUC)排序。总的来说,本例中的所有模型都表现得非常好,性能上存在相当细微的差异。然而,输入数据的规模变化很大。最值得注意的是,仅使用两个变量(PC1和PC2)的模型的AUC>0.97,非常接近AUC>0.99的最佳模型。
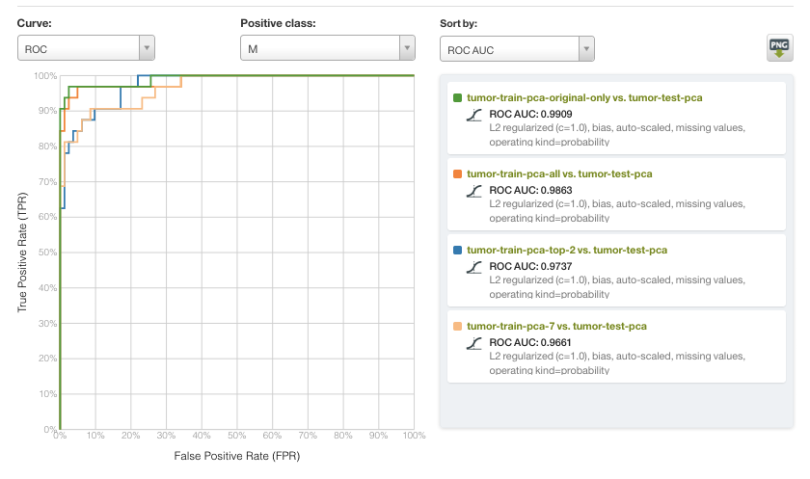
作为奥卡姆剃刀在机器学习中,尽可能使用更简单的模型通常是有利的。基于PCA的降维是一种方法,它可以在保持大部分相关信息内容的同时,使用更少的特征构建模型。因此,我们邀请您使用自己的数据集探索新的PCA功能,既可以用于探索性可视化任务,也可以作为预处理步骤。
想了解更多关于PCA的知识吗?
如果您想了解有关主成分分析的更多信息并在BigML平台上看到它的实际应用,请为我们即将在beplay2网页登陆2018年12月20日,星期四. 出席是免费的,但空间有限,所以尽快注册!
