如果你是大约5400万美国人中的一员,填写了一个预测今年NCAA男子篮球锦标赛的括号,那么你的括号很可能在锦标赛的前24小时内不再完美,并且在开幕周末结束时基本偏离了轨道。正确预测所有63场比赛(忽略4场比赛)是难以捉摸,概率范围从1/9.2到1/1280亿,这取决于谁在统计。在如此低的赔率下,毫不奇怪沃伦自助餐著名的是,他向每一位正确选择获胜者的人提供了10亿美元的奖金。
不熟悉NCAA篮球锦标赛的运作方式?现在是暂停并查看此内容的好时机指导.

今年,这项赛事再次实现了其“三月疯狂”的绰号,在前两轮比赛中,许多热门选手输了。这场混乱是由一名记者主导的空前的沮丧在第一轮比赛中,远射的UMBC以1名种子选手维吉尼亚获胜,并声称1名泽维尔、2名北卡罗来纳州和2名辛辛那提为受害者。由于如此多的括号被正式取消,我们决定研究机器学习方法在预测剩余比赛中的表现。
数据收集与特征工程
在几乎所有的数据分析项目中,数据采集和争论构成了最大的挑战和时间需求。幸运的是,NCAA篮球比赛的结构良好的数据集——可以追溯到1985赛季——已经由卡格尔和肯尼斯·梅西. 虽然这些数据的格式不能被视为“机器学习就绪”,但它确实为设计特征提供了大量的原材料。我们的方法是将每一支球队表示为一个工程特征列表,这样过去的每一场篮球比赛都可以通过两个列表(每支球队一个)和一个客观场的组合来表示,该客观场由所列第一支球队的比赛结果组成。因为我们的许多特征都依赖于2003年季节收集的数据,所以我们将最终数据集限制为最近15个季节采集的118个特征。

本次调查中使用的特征属于几个不同的类别:
- 团队绩效:e、 例如,主客场胜利、近距离比赛中的胜利、最长连胜、得分差等。
- 游戏统计:e、 例如,罚球命中率、三分球命中率、平均三分球命中率、平均篮板差等。
- 排名信息:e、 g、RPI、锦标赛种子、Whitlock、Pomeroy、Sagarin等。
模型培训和评估
在每个赛季都可以独立考虑的假设下,我们使用历史NCAA锦标赛和2003年常规赛数据,训练并比较了BigML提供的四种不同的监督机器学习算法。使用beplay2网页登陆Python包,我们采用了一种独特的交叉验证方法,即使用所有其他比赛的比赛数据作为训练数据来预测每场比赛的结果。假设有15个季节的训练数据可用,得到的评估结果类似于15次交叉验证,如下面的箱线图所示。默认参数用于研究的四种算法:随机决策森林,扶植树木,逻辑回归和深海网.

虽然这些算法的性能彼此相似,但我们最终决定应用深海网因为它具有最小的季节差异和最大的最低性能,也就是说,与其他方法相比,它很少表现不佳。
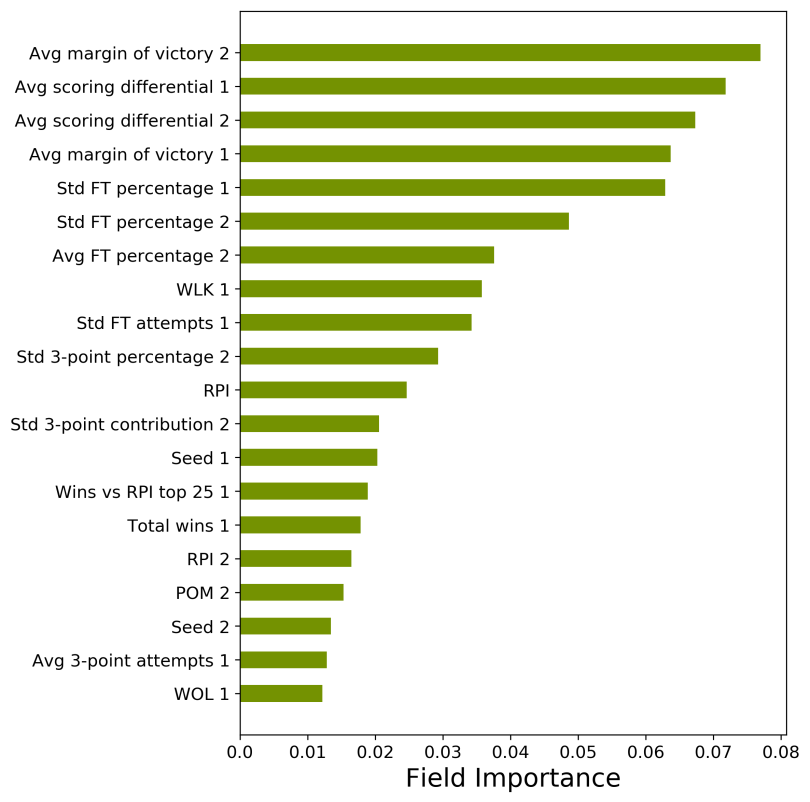
在调查领域重要性有趣的是,在这个模型中,团队种子并不是最重要的特征,尽管两者都排在前20名。这表明我们的模型将返回预言这不仅仅是比赛中的种子。前四个特征是相当一致的:各球队的平均得分差和获胜差距。这一结果表明,与过去是否获胜相比,你在比赛中获得的分数可能是未来获胜的更大指标。因此,拥有许多井喷式胜利的团队可能比拥有同等记录但以较小的优势获胜的团队表现更好。在顶级功能中没有“接近的胜利/失败”表明,接近的比赛可能更多地是由偶然而非决定决定的。
最后,许多不同的排名系统,包括RPI、WLK(Whitlock)、WOL(Wolfe)和POM(Pomeroy),都被发现在顶级特征中。应该注意的是,虽然这些系统中的每一个都使用不同的方法对球队进行排名,但它们彼此之间以及比赛中的种子都有着高度的相关性。如果有兴趣,您可以查看这些不同的排名系统以及它们之间的比较。
深海网架预测
填写NCAA锦标赛当然不需要算法,而且存在一些流行的启发式方法,它们在不同程度上取得了成功。而一些直觉的结合,母校忠诚,甚至吉祥物偏好通知大多数括号内的决定,默认的选择方法只是选择较低的种子。虽然这种模式在我们的机器学习生成的预测中基本保持不变,但这种方法的有效性在最初几轮通过后就会失效,团队变得更加平等匹配。在一场典型的等级赛中,这也是得分最多的回合。
除了根据我们的模型挑选每场比赛的获胜者外,我们还对每支球队获胜的概率进行了颜色编码。颜色的强度表示结果的概率,红色和浅色表示结果的可信度较低。

虽然我们的模型的预测总体上是保守的,但它并不总是选择较低的种子。在东部和中西部地区,维拉诺瓦和杜克有望晋级四强,尽管预计这两支精英8强的对手信心都不会比掷硬币高出多少。在南方,我们的模型更喜欢堪萨斯州,而不是排名较低的肯塔基州,尽管内华达州被选中晋级半决赛。最后,在西部地区,我们的deepnet模型对Gonzaga和Michigan Advanced有相当大的信心,总体上更倾向于Michigan。我们预计的冠军赛是十大锦标赛冠军密歇根州和常年竞争对手杜克之间的较量,蓝魔鬼队在4月2日赢得了第六个全国冠军。
锦标赛模拟
虽然预测一场比赛的离散结果是一项令人信服的工作,但NCAA锦标赛中混乱的频率提醒我们,即使是非常罕见的事件不可避免地发生.下一步是探索返回的概率通过我们的模型更详细地描述。
根据我们的模型返回的匹配概率,我们可以将每个游戏模拟为“不公平”的抛硬币,而不是简单地假设总是会出现更高概率的结果。也就是说,如果维拉诺瓦以73%的概率击败西弗吉尼亚,西弗吉尼亚仍有相当大的机会(27%)前进。通过以这种方式模拟锦标赛游戏,我们可以根据预测发生的可能性在预测中引入混乱。最后,我们模拟了锦标赛的剩余比赛10000次。下表总结了结果。

由于比赛后几轮中的事件概率代表复合概率,我们看到的结果乍一看可能与上面给出的括号不一致。例如,尽管维拉诺瓦在一场迎头对决中比普渡更受青睐,但普渡*仍然拥有赢得整个锦标赛的最高概率。这反映了两个因素:
- 普渡大学比维拉诺娃更有可能晋级16强。
- 在最后四轮比赛中,与锦标赛中其他球队可能面临的结果差异。
*不幸的是,我们的模型在这一点上没有考虑关键球员受伤的复杂程度,也没有使用前两轮比赛的数据进行更新。许多专家一致认为,在7英尺2英寸的中锋艾萨克·哈斯受伤后,普渡大学的机会受到了重大打击,除非普渡大学工程师可以拯救这一天.
最后的想法
虽然依靠机器学习模型来预测括号远不是一个确定的策略,但它可以提供另一种方法来做出有趣而引人注目的选择。通过强调事件发生的概率,而不是离散的结果,我们可以更好地了解不安的频率。最终,知道谁将赢得锦标赛的唯一方法是玩游戏。
