机器学习是加速其从学术界过渡到工业。我们看到越来越多的媒体报道,但多数时候他们只关注最终结果而不是在幕后发生的所有人力任务,真正使魔术成为可能。所以对大多数人来说机器学习仍然是某种形式的难以捉摸的魔法。我们最近接洽,《国家报》的Vodafone-sponsored部分,解释机器学习是如何工作的,给它一些思想后,我们决定使用一个简单的例子来解释它在一个域每个人都熟悉。随着电影艺术与科学学院第89届奥斯卡奖仪式的临近,世界各地的影迷为他们做准备办公室池,我们不能抵制诱惑,尝试预测2017年奥斯卡通过应用一些BigML-powered机器学习由自己的特蕾莎修女阿尔瓦雷斯和坎Zuriaga多。beplay2网页登陆
当然,拿奥斯卡奖得主每年冬天都仍然是许多人最喜欢的消遣方式。像往常一样,没有什么意见,从那些短缺电影评论家来饮剂唐纳德·j·特朗普来建立媒体发布更多的数据驱动的分析。一件事,许多这些水晶球的共同点是他们都没有给读者访问底层数据,逻辑或模型。时间让我们改变的更好!
购者自慎
没有模型是完美的,所以在我们去揭示,警告。
这个练习的主要目的是演示的过程通常是为了使预测使用机器学习。
奥斯卡提名和投票选择赢家的学院成员。模型正确模型这一问题,我们也应该学会成员和所有的因素,影响他们如何选择他们最喜欢的电影。然而,我们努力限制公开关于电影的信息,而不是学院成员。
此外,问题本身的性质是不断变化的。学院不是一个整体结构和成员的尸体,规则,适用于提名,投票过程可能发生变化在过去的几年里。一个很好的例子是最近的引入新批学院成员在应对投诉缺乏多样性。所以过去的行为并不总是最好的预测未来的行为。
- 最后,口味变化。可以认为,“奥斯卡”比其他电影产业具有较强的根源在于传统奖项,但是我们不能否认,在一个时代是什么不能保证翻译到另一个没有任何变化。在我们数字时代,它不再是一个空想想象一个小预算艺术电影发布正确的时间在正确的节日和骑大浪潮的口碑推广社交媒体终于从大片抢出风头,主要电影制片厂提供资金。他们是一个'changin的美好时光!
所以让我们开始吧!
1。问题定义和上下文理解
说明预测问题是任何机器学习工作流程,最重要的一步,因为它完全形状我们的解决过程的其余部分。预测奥斯卡奖得主可以建模为一个分类的任务,也就是说,我们需要创建一个预测模型,鉴于2016年发布的电影将输出“是的”当它预测,获得奥斯卡奖的电影“不”否则。在预测今年的奥斯卡奖得主,我们决定限制我们的预测只有8的24授予类别。
下一步是收集和准备一些数据关于电影,是什么让他们过去那些大奖,以及这些属性2016部电影。上下文和业务问题的理解越多,你越准备来决定哪些数据收集。两个商业洞见引导我们的数据收集过程:
- 总数的约600部电影提名自2000年以来,62%是来自美国平均50美元的预算,欧盟预算,超过3倍高于拉丁美洲国家的20倍。

- 预算金额与后续相关收入的电影,但它似乎并没有赢得奥斯卡强烈相关。此外,分析期间的差异之间的平均预算电影赢得奥斯卡奖和那些不变化很大。所以我们并不期望预算是我们模型的一个重要因素。
2。数据收集和数据转换
在几乎所有的机器学习项目中,最耗时的任务是收集和结构化数据。在我们的例子中,由于时间限制,我们预计,我们留下了很多数据,预测可能非常有价值。例如:女演员和演员与先前的提名和奖项,或者奥斯卡之前收到的提名导演,编剧,等等。它也是非常重要的选择在你的训练数据应该走多远;不会足够远可能意味着丢失一些有用的东西,但是走得太远会接模式可能不再相关的业务我们有时称之为坏实践“做考古学”)。我们决定用电影在2000年和2016年之间。
这段时间,我们编译的数据集相结合:
- 电影流派等元数据,预算等以及用户评级和评论IMDb每年的50个最受欢迎的电影
- 每年的提名和赢家20关键行业奖项,包括奥斯卡奖,金球奖,英国电影学院奖,演员工会,批评人士的选择,导演协会,生产商协会,艺术导演协会,作家协会、服装设计师协会、在线电影电视协会、人民的选择,伦敦评论家圈,美国电影编辑,好莱坞电影,奥斯汀影评人协会、丹佛影评人协会、波士顿影评人协会、纽约影评人协会,洛杉矶影评人协会。
额外的复杂性,为数据评级和评论,很难确定是否影响这部电影是获得奥斯卡提名。换句话说,我们没有能力重建我们的数据建设的确切时间表。
我们还必须注意,尽管我们尽了最大努力净化数据集,可能仍有一些不准确的数据本身。最后我们编辑的数据集,是一个相当小的行数,由于问题的性质(毕竟这是一个每年一次事件每年有一组不同的选手)。这使得模型容易产生噪音和过度拟合,即使选择乐团作为我们的算法在一定程度上缓解了这一风险。你可以通过访问我们的输入数据集这个Bigbeplay2网页登陆ML共享链接或通过BigMbeplay2网页登陆L画廊的数据集在这里。

3所示。数据探索
很好的热身运动在任何预测数据的任务是一个视觉熟读。一个这样的捕鱼活动使用beplay2网页登陆BigML协会发现能力得到了一些有趣的关联:
提名最佳影片通常是戏剧和传记,很少动作电影。的赢家,我们并没有发现很强的相关性与流派提名以来已经属于一个紧群类型。
当使用协会发现找到最重要的奥斯卡颁奖典礼和其他奖项之间的相关性,我们看到特别显著的相关性与金球奖或者评论家选择奖,其他几个人之一。
- 见下面的散点图,和更高的票房并不总是看电影或者更多的选票赢得奥斯卡最佳影片。
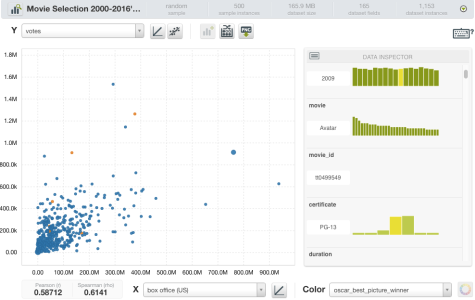
- 类似的事情发生在用户和评论家的评论:
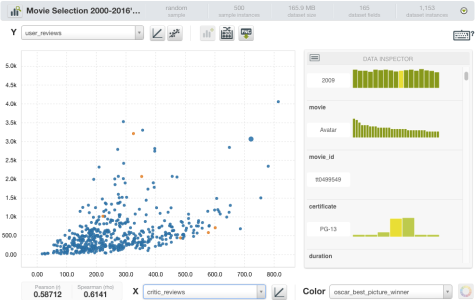


4所示。工程特性
大多数数据集可以富含一些额外的特性,来自现有的,可以增加数据的预测能力。在我们的例子中,由于非结构化影评可以挑战分析,我们跑IMDb数据通过用户评论主题模型分析自动发现的一组主题可以用来描述每个数据行。对每个电影的主题和它们的关联概率作为新功能添加到我们的数据集。总的来说,我们的机器Learning-ready数据集是由256个不同的领域自2000年以来生产1152部电影。一旦准备好了,数据集建模和评估任务成为easy-peasy-lemon-squeezy BigML。beplay2网页登陆

5。建模
通常预测建模涉及比较和选择合适的分类算法和具体的参数。这个过程可以完全自动化,尽管你需要注意的炒作在全自动。在我们的例子中,试了几次后,鉴于我们有限的历史数据和需要避免过度拟合,我们选择了在决策树树集合体或逻辑回归。8所以我们创建单独的二进制分类模型(每个奖项类别一个)与目标字段(列我们想要预测)是“赢家”。
6。评价
评估每组变量的预测影响每个类别(例如,元数据、评级、评论公布最佳影片得主),我们采取了分段的方法,我们做了不同的预测基于不同的乐团建立在不同的数据集的子集。这种方法给我们的贡献不同类型数据的最终预测相结合,并帮助指导我们齐心协力的努力更多的数据在需要的时候在某些方面。例如,发现关注奖数据会产生更好的效果,翻译成更多的奖历史数据的收集更好的最终预测。
评估我们的分类模型,我们使用周期在2000 - 12财年培训期间,和2013 - 15测试周期。然后我们输入的数据2016年提名已经验证乐团抵达我们的最终预测。

评价结果表明,结合所有可用的变量产生最好的结果从本质上减少误报,同时保持一个非常高的真正积极的命中率。

7所示。预测:鼓请滚…
我们终于看到我们的模型发现什么!

看来每个人的情感最喜欢的音乐La La土地将有一个大奖给备案14今年收到的提名。当我们深入研究这一预测背后的主要动力,我们观察到评论家选择提名和奖项收到其他表现奖(与制片人协会、演员工会和BAFTA尤其突出)解释原因La La土地最喜欢的是很高吗F-measure引导。

但是,如果我们深入和看看non-award数据预测我们看到不同的画面,在IMDb支持用户评论围栏,和奖提名强调小预算月光。但当实际奖奖金添加所有的因素相结合,La La土地出现的# 1的选择。我们可以在周日晚上一个惊喜吗?也许是这样,但它必须是一个史诗般的难过,所以机会非常低。

现在我们已经揭开神秘的面纱关于最期待的奖项的夜晚,让我们快速回顾剩下的类别。

没有大的惊喜和达米安Chazelle将拿起最佳导演奖项符合他的成功在颁奖circuit-especially导演协会。

最佳女演员艾玛·斯通携带的统计La La土地甚至更高。再次,金球奖和演员工会皮卡是最大的力量向前推她的提名。

今年的最佳男主角是千钧一发之间卡西·阿弗莱克(曼彻斯特在海边)和丹泽尔·华盛顿(栅栏),从而降低了预测的信心。演员工会奖将丹泽尔·华盛顿对他肯定有影响,但凯西阿弗莱克在总捡了更多的奖项,每我们的模型,这似乎帮助他得到一个轻微的边缘。我们只发现周日奥斯卡的判断是否被蒙蔽了个人问题阿弗莱克尽管大多数人认为是一个杰出的表演表现。

维奥拉戴维斯(栅栏最佳女配角)是大众最喜欢的BAFTA主要是由于她的表演,演员工会奖和纽约评论家圈。

最佳男配角奖是另一个范畴的可行选择。我们的选择是Mahershala阿里(月光)。大多数评论家似乎强调Mahershala阿里和戴夫·帕特尔的最爱这一类。Mahershala阿里有点残疾的模型,因为他没能接这一类的金球奖,这转化为一个相当低的信心值预测。有趣的是,夜间活动的动物演员亚伦Tayor-Johnson赢得金球奖,但他甚至不是一个奥斯卡提名。实际上,我们犯了一个错误在我们的一个初步的模型输入对迈克尔·香农和金球奖获胜,因为这被提名最佳模型,我们的模型预测他是获胜者。这是有助于提醒我们小心你不仅需要收集和清洗的数据训练模型,但也确保您输入正确的预测。

最佳原创剧本也在玩La La土地和曼彻斯特在海边争夺这个奖项。La La土地似乎有一个很轻微的边缘的英国学院奖,但不要指望了曼彻斯特在海边。

最后,最佳改编剧本可能会去到来自从电影奖项类别的电路中做得很好。
经验教训
除了一个有趣的任务,这个练习进一步证明了合作的力量和重要性正确的数据集和工程由于关注功能。能够构建最佳特性仍是最大的投资回报的时间,尤其是在坚实的存在像BigML机器学习平台:beplay2网页登陆
- 一些有史以来最通用的算法提供了通过一个直观的界面(以及彻底API)。
- 可伸缩性问题抽象为终端用户专注于手头的分析任务。
- 灵活的部署选项使它成为一个微风实施选择模型处理正确的数据。
工程在一天结束的时候,特性是反映真正的专业知识在一个给定的域模型构建。
我们希望你会发现这些预测有用,因为你拿一杯酒和遵循Jimmy Kimmel周日开始的仪式。祝你好运与您的选择!

